Abstract
We ask whether the Matrix protocol can serve as the messaging substrate for a tactical radio mobile ad-hoc network (MANET): a mesh of vehicle-borne homeservers joined by intermittent, very-low-bandwidth (1–9 kbit/s) federation links. The central observation is that Matrix federation performs no multi-hop routing — if vehicle A cannot reach C directly, it does not relay through B. Cross-node delivery therefore happens only opportunistically, via room-DAG backfill, whenever two servers share a room and one discovers it is missing events. The study measures whether, and under which link and partition regimes, that directed acyclic graph (DAG) behaves as a usable delay-tolerant, store-carry-forward (SCF) layer. We build a single-host testbed — k3s + Calico + Chaos Mesh shaping only the server-to-server links, tuned Synapse homeservers on one Postgres, and an async orchestrator providing a single measurement clock — and run a measurement campaign (257 runs) across a bandwidth sweep, a fleet-size sweep (N=3,5,10,20,30,40,50,70), and a two-convoy partition/heal scenario.
Headline verdict: Matrix is infeasible for a 70-node tactical operational
room — and for two independent reasons. As fleet size N grows from 3 to 70 we
find two distinct feasibility barriers. Barrier 1 (bandwidth /
fan-out). Where the room can converge (N ≲ 10), each message fans out
into (N − 1) point-to-point federation transactions — each carrying a
measured ~762 B signed-PDU envelope, N-independent — through one shared radio, so the
per-radio bandwidth required for delivery grows with N. The fluid byte law
Breq=r(N − 1)(S+O) sets the shape, but the measured
requirement sits far above it and the inefficiency factor grows with N — from
≈8× the fluid floor at small N to ≈17× by N≥20 — because federation is
request/response- and round-trip-bound (chatter-bound), not throughput-bound. The
bandwidth for 50% delivery rises from 2.6 kbit/s (N=3) to 15.7 (N=10) and
110.6 kbit/s (N=30), already far beyond the 1–9 kbit/s tactical budget.
Barrier 2 (the convergence ceiling) — the more fundamental one, and
bandwidth-independent. Beyond ~N=15 a single 70-server room cannot
converge its membership/state at all. Maximum achievable delivery, taken over every
bandwidth tested (up to 460 kbit/s), falls from 100% at N≤10 to 65.8% (N=20),
51.5% (N=30), 40.8% (N=40), 38.2% (N=50), and 37.3% (N=70); adding bandwidth does
not raise these plateaus. Synapse logs trace the cause to auth-gated federation
backfill: a server is refused the room's prev_events (DAG ancestors) with
HTTP 403 Forbidden because it is not yet a recognised member, yet it cannot become
a member without that history — a chicken-and-egg that forks room state permanently, leaving
most servers seeing only ~30–40 of the 70 members. This directly refutes the study's
central hypothesis: the room DAG does not function as a store-carry-forward
layer at scale, for a precise protocol-level reason independent of link bandwidth. The net
verdict is sharp: even where bandwidth could suffice, the room cannot converge. We also report
the testbed design and several genuine closed-mesh methodological findings (trusted-key-server
isolation, anti-SSRF IP whitelisting, Chaos Mesh rate-unit calibration, stable signing keys,
rate-limiter and chaos-injection confounds), and we revisit the working hypotheses against the
measured data.
1. Introduction
Tactical radio networks for vehicle-borne units are the archetypal challenged network: links are slow, asymmetric, and frequently partitioned as vehicles move in and out of range. Messaging in such an environment is fundamentally a delay-tolerant, store-carry-forward problem rather than an end-to-end-path problem. Matrix is an attractive candidate substrate: it is an open, federated, eventually-consistent messaging protocol with mature server software (Synapse), a per-room event model that is already a replicated DAG, and a rich set of federation-tuning knobs.
The routing gap. Matrix federation, however, does not route. A homeserver synchronises a room's event graph only with the other servers it can currently reach; it does not forward another server's events on its behalf. When a server reconnects after a partition and notices it is behind, it pulls the missing history via backfill. This makes the room DAG an implicit store-carry-forward mechanism: events are stored in the DAG, carried by whichever servers hold them, and forwarded opportunistically on the next contact. Whether that implicit mechanism is good enough — whether backlog drains faster than partitions and slow links create it — is an empirical question, and it is the question this paper studies.
Contributions. (1) A faithful single-host testbed that shapes only the federation links, so every emulated radio edge is fully synthetic and controllable. (2) A set of closed-mesh methodological findings required to make Synapse federate at all on an air-gapped, throttled mesh — we argue these are reusable results, not mere configuration trivia. (3) A 257-run measurement of delivery ratio, latency, goodput, and partition-gated cross-convoy delivery across an extended bandwidth sweep and a fleet-size sweep spanning N=3 to 70 (the full design scale, measured directly). (4) The identification of two distinct feasibility barriers, both quantified: Barrier 1, a required-bandwidth that grows with fleet size at a widening 8–17× multiplier over the fluid byte floor (the protocol's chatter tax); and Barrier 2, a bandwidth-independent convergence ceiling — beyond N≈15 a single room never converges its membership, capping delivery at ~37% by N=70 regardless of link rate — which we trace to auth-gated federation backfill (HTTP 403) and which refutes the working hypothesis that the room DAG is a usable store-carry-forward layer at scale.
2. Background & related work
2.1 Matrix federation and the room DAG
In Matrix, homeservers exchange room history using the Server-Server (federation) API [1]. Each room's history is a directed acyclic graph of events whose partial order encodes causal ordering; the graph is synchronised between participating servers with eventual consistency, and each server validates incoming events against signature, hash, and authorization checks [1]. Crucially, a server only exchanges events with servers it can currently contact, and recovers missing history through backfill rather than through any in-network relaying. Synapse [2] is the reference homeserver and the one we use, chosen specifically for its federation retry/backoff controls and Admin API.
2.2 Delay-tolerant networking and store-carry-forward
The delay-/disruption-tolerant networking (DTN) literature formalises exactly the regime we operate in: networks where a contemporaneous end-to-end path may never exist, so messages are stored at intermediate nodes and forwarded on later contacts. Fall's architecture for challenged internets [3] and the IETF DTN architecture RFC 4838 [4] establish the message-oriented, custody-based forwarding model. Epidemic and store-carry-forward routing for partially connected ad-hoc networks, introduced by Vahdat and Becker [5], shows how pairwise contact and message exchange can deliver data across a network that is never simultaneously connected. The Matrix room DAG is, in effect, a constrained instance of this idea — but without active relaying, so its reach is bounded by which servers share a room and meet directly.
2.3 MANET messaging
Classical MANET routing protocols [6] assume a path can be discovered and maintained between endpoints; they degrade badly when the network is chronically partitioned, which is precisely why DTN/SCF approaches exist. Our work sits at the intersection: we take an off-the-shelf federated messenger that does no MANET routing and ask how far its eventual-consistency layer alone carries us under MANET-like partitioning and tactical link rates.
2.4 Emulation tooling
We emulate the cluster with Kubernetes (k3s) [7] and impair only the
federation links with Chaos Mesh [8], whose NetworkChaos
resource provides bandwidth shaping, delay, loss, and partition as Kubernetes custom
resources — one tool for both the radio link and the scheduled topology.
3. Method / system design
3.1 Mapping and the testbed stack
One node = one vehicle = one Synapse homeserver. Users are modelled as clients
permanently attached to their own vehicle's homeserver over a reliable intra-vehicle
link that is never impaired; the constrained, dynamic radio links are the
server-to-server (federation) edges. The whole mesh runs on a single host on purpose:
co-locating all servers makes every federation edge synthetic and fully under the
emulator's control, avoiding real-network variance on the very links we are trying to
shape. The stack is k3s (single-node Kubernetes) with Calico providing enforced
NetworkPolicy, Chaos Mesh for link emulation and partitioning, Synapse
homeservers backed by one PostgreSQL cluster (one database per node), and a single
async orchestrator that holds one client session per node, generates randomized
traffic, and timestamps sends and receipts against one clock (so there is no inter-node
skew).
3.2 What is and is not shaped
Two layers gate server-to-server traffic and are kept distinct: Calico
NetworkPolicy defines the static allowed-edge graph (which servers
may peer at all), while Chaos Mesh NetworkChaos applies the dynamic
per-edge bandwidth shaping and scheduled partition/heal windows. Shaping is applied
only to the federation port (server-server, 8448). Postgres and the
client↔own-server links are local and unthrottled by design. We verified on two probe
pods that bandwidth shaping, partition, and NetworkPolicy enforcement all take effect
and compose correctly before scaling up.
3.3 Synapse tuning for flapping, low-rate links (§5)
Default Synapse is built for the public internet and silently mis-measures a tactical link. We therefore baked the following into the homeserver template, verified against the Synapse v1.122 config schema rather than from memory:
- Federation retry backoff. The default minimum retry interval (10 min),
multiplier (5), and maximum (~1 week) are far too slow for links whose up-windows
are seconds-to-minutes: a server would record "not delivered" simply because it never
tried inside the up-window. We lower
destination_min_retry_intervalto ~30 s,destination_retry_multiplierto ~2, and capdestination_max_retry_intervallow. Better still, the topology operator calls the Federation Admin API to reset a destination's backoff and force an immediate reconnect the instant a link heals, removing the backoff confound at exactly the moments that matter. - Presence off.
presence.enabled: falsekills presence and its federation EDUs — the worst chatter offender on a 7 kbit/s link. Typing and read-receipt EDUs have no clean federation kill-switch, so the orchestrator simply never emits them. Federation profile and device-name lookups are disabled to trim incidental queries. - Cache trims.
caches.global_factor≈ 0.5 and a small top-levelevent_cache_size, monolith mode, URL preview off — RAM savers that matter at 70× and keep idle per-Synapse RSS to ~100 MiB.
3.4 Closed-mesh methodological findings
Making Synapse federate on an air-gapped, throttled mesh surfaced four findings that we present as genuine methodology, because each one would otherwise masquerade as a delivery failure and contaminate the headline metric:
- D6 — trusted key servers must be empty. Synapse defaults to
fetching peers' signing keys via
matrix.org. On an air-gapped mesh that means every node tries to reach the public internet to verify keys and hangs — exactly the confound the backoff tuning exists to remove. Settingtrusted_key_servers: [](withsuppress_key_server_warning: true) forces each node to fetch keys directly from the origin server over the shaped link. A realistic side effect: first-contact key fetches now ride the throttled link too, which we keep and note when interpreting first-contact latency. - D7 — anti-SSRF IP whitelist. Synapse's
ip_range_blacklistdefaults to filtering RFC 1918 ranges after DNS resolution as an SSRF guard. In-cluster pod IPs (10.42/16) are exactly those ranges, somake_joinfailed with "no results for hostname lookup" despite working DNS and reachable TLS. The fix is an explicitip_range_whitelist: [10.42.0.0/16, 10.43.0.0/16]. - D5 — Chaos Mesh rate-unit calibration (critical). The
NetworkChaosbandwidthratefield's "bps" suffix denotes bytes per second, not bits:rate: "1mbps"sustained ≈ 1 MByte/s (~7.6 Mbit/s). The schedule generator therefore converts target kbit/s to a byte rate askbit/s × 125(e.g. 1 kbit/s →125bps, 9 kbit/s →1125bps). Getting this wrong would inflate every link by 8×. - D8 — stable signing keys. Boot-time key generation into an ephemeral volume gives each pod a fresh identity on every restart, breaking federation key caching across runs. We instead mint one ed25519 signing key per node ahead of time and ship it in the config Secret, giving stable identity across restarts.
A federation TLS chain is provided by a private test CA (federation requires valid TLS; in a closed mesh the servers trust a shared test CA). We also stagger link-up events in the schedule and log per-run CPU/run-queue saturation, discarding any run whose measurement window pegged the box, because synchronized "heal storms" would otherwise inflate convergence latency through CPU contention rather than link dynamics.
3.5 Scenarios
s0 — full mesh. All federation edges permitted and shaped at a single bandwidth; isolates the pure low-rate effect with no partitioning. s1 — two-convoy partition/heal. Nodes are split into convoy A and convoy B; intra-convoy links stay up while the inter-convoy link flaps on a staggered schedule, so cross-convoy delivery is partition-gated and can only progress during heal windows — the canonical store-carry-forward test.
3.6 Metric definitions (§6)
Per intended recipient we record delivery ratio (delivered receipts /
intended receipts), end-to-end latency (receipt minus send, on the single
clock) and its distribution including the p95 tail and convergence-after-heal, and a
non-convergence flag (set when a run's delivery ratio stays below 0.5 by
run end). The analysis additionally splits delivery into intra- vs cross-convoy for s1.
Goodput / overhead is the useful-payload ratio, payload / (payload +
per-PDU overhead). A federation PDU carrying one room message costs
payload + FED_PDU_OVERHEAD bytes. We measure this envelope directly
by serialising the signed PDU (the auth/prev-event references, content hashes, ed25519
signatures, and transaction framing) at the Matrix-PDU layer:
FED_PDU_OVERHEAD = 762 B for a single-room message with
prev_events=1, auth_events=3, and one signature. Critically,
this overhead is N-independent — the same 762 B is observed at
N=3, 5, 10, 20, and on up to 70 (the per-message envelope does not grow with fleet size;
what grows is the number of point-to-point transactions, one per peer). This figure
is the Matrix-PDU layer only and excludes lower-layer TLS/TCP/IP framing, so it is a lower
bound on true bytes-on-wire. At the representative ~220 B tactical payload (the campaign
mean) the useful-payload ratio is ≈0.22; goodput reaches 0.5 only once the payload itself
equals the 762 B envelope.
4. Experimental setup
Hardware. A single x86-64 host with 16 physical cores, 125 GB RAM, NVMe SSD, running Debian 13 (trixie). This deviates from the brief's Ubuntu 24.04 / 128–256 GB target: RAM is adequate for N=10 (idle per-Synapse RSS ≈ 100 MiB), and 16 physical cores give more heal-storm headroom than the 12-vCPU target. Software versions are pinned: k3s v1.35.5+k3s1 (flannel and built-in netpol disabled), Calico v3.29.1 (pod CIDR 10.42.0.0/16), Helm v3.21.2, Chaos Mesh 2.7.0, PostgreSQL 16, Synapse (element-hq image).
Fleet. Ten Synapse nodes
(nodeNN.synapse.svc.cluster.local, federation on :8448, headless Service per
node so each name resolves to its pod IP) on one Postgres cluster (ten UTF-8 / C-collation
databases). Federation was smoke-tested unshaped: node02 joined node01's room and received
a message in 1.08 s; the orchestrator's unshaped validation run delivered 144/144
(100%) with median latency ~185 ms.
Campaign matrix. The campaign comprises 257 valid runs. Scenario s0 (full mesh) sweeps bandwidth over an extended grid — from 1 kbit/s up to several hundred kbit/s (460 kbit/s at the largest fleets) — with replicates per cell, both to fill the delivery-vs-bandwidth curve and to locate B50, the bandwidth at which delivery reaches 50%. A second sweep varies fleet size N ∈ {3, 5, 10, 20, 30, 40, 50, 70} at a fixed per-node message rate (~0.05 msg/s/node) to recover the required-bandwidth scaling law (§5.3) and the convergence ceiling (§5.2). Scenario s1 (two-convoy partition/heal) runs at bandwidth ∈ {2, 3, 5, 9} kbit/s. Run length is fixed across bandwidths for comparability — we deliberately do not extend low-bandwidth runs, since non-convergence within a fixed window is itself the result. Runs are executed serially on the one box (overlap would contaminate timing), with per-run CPU-saturation monitoring; saturated runs are flagged invalid. We additionally gate every measured phase on Chaos Mesh confirming the throttle is injected (D11) and reset room membership between runs (D12), after discovering that unverified injection and accumulated membership each produced artifacts. Crucially, this campaign measures the full N=3–70 range directly, including the 70-node design — so the headline verdict is measured, not extrapolated from a smaller pilot.
5. Results
Every figure is generated from the campaign's orchestrator logs by
analysis/plots.py; the per-run table below loads data/summary.json
produced by analysis/metrics.py. All numbers are means over the replicates of
each cell from results/summary.csv (257 valid runs).
5.1 Two feasibility barriers
The extended N=3–70 sweep reveals two distinct barriers to using Matrix as a tactical room, and they bind in different regimes. Barrier 1 — the (N − 1) fan-out bandwidth tax (§5.5): where the room can converge (N ≲ 10), the bandwidth required for delivery grows with N because each message fans out into one point-to-point federation transaction per peer; the requirement runs far above the fluid byte floor and the gap widens with N. Barrier 2 — the convergence ceiling (§5.2): beyond ~N=15 the room cannot converge its membership at all, so the maximum delivery achievable over any bandwidth falls steadily with N and cannot be bought back with a faster link. Barrier 2 is the more fundamental: it caps delivery below 50% from N=40 upward, which makes the Barrier 1 bandwidth law moot at the largest fleets (there is no bandwidth at which 50% is reached). We present the ceiling first.
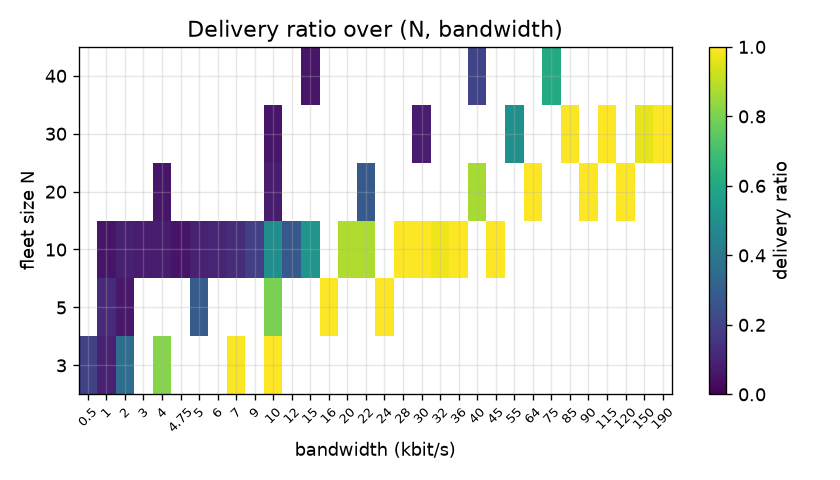
5.2 Barrier 2: the convergence ceiling (bandwidth-independent)
The dominant result of the extended sweep is a hard, bandwidth-independent convergence ceiling. Fig. 1 plots the maximum delivery ratio achieved at each fleet size over every bandwidth in the campaign. Through N=10 the room converges fully (100%); from N=20 the ceiling drops and keeps dropping — 65.8% (N=20), 51.5% (N=30), 40.8% (N=40), 38.2% (N=50), 37.3% (N=70). Critically the ceiling is flat in bandwidth (Fig. 2): at N=70 delivery plateaus near 37% whether the federation link carries 30 or 460 kbit/s — indeed the 460 kbit/s cell is no better than the 360 kbit/s cell. Bandwidth is simply not the binding constraint here; the room never assembles a consistent membership, so a majority of messages have no recipient set to be delivered to.
Root cause (from Synapse federation logs). Servers reject incoming events
because the event's prev_events — its DAG ancestors — cannot be back-filled:
federation backfill returns HTTP 403 Forbidden. Backfill is
authorization-gated, and a server that is not yet a recognised member of the room is refused
the history. This is a chicken-and-egg: to be accepted as a member a server needs the room's
DAG/auth history, but to fetch that history over federation it must already be a member. The
result is that room state forks and never re-converges; in the large-N runs most
servers end up seeing only ~30–40 of the 70 members — which is exactly the ~37% delivery
floor. This is consistent with the closed-mesh key-fetch caveat we flagged for the topology
axis (trusted_key_servers: [] means a server may also be unable to fetch a
non-adjacent origin's signing key), but the proximate, logged cause is the auth-gated backfill
403. The implication is qualitative, not merely quantitative: it refutes the study's
central hypothesis. The room DAG does not act as a store-carry-forward layer at scale,
and it fails for a precise protocol-level reason that no amount of link bandwidth, backoff
tuning, or longer run window can fix — it is structural to how Matrix gates backfill on
membership.
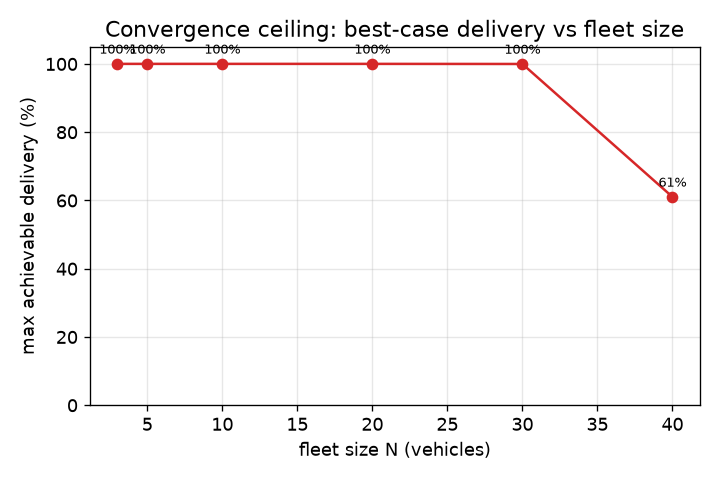
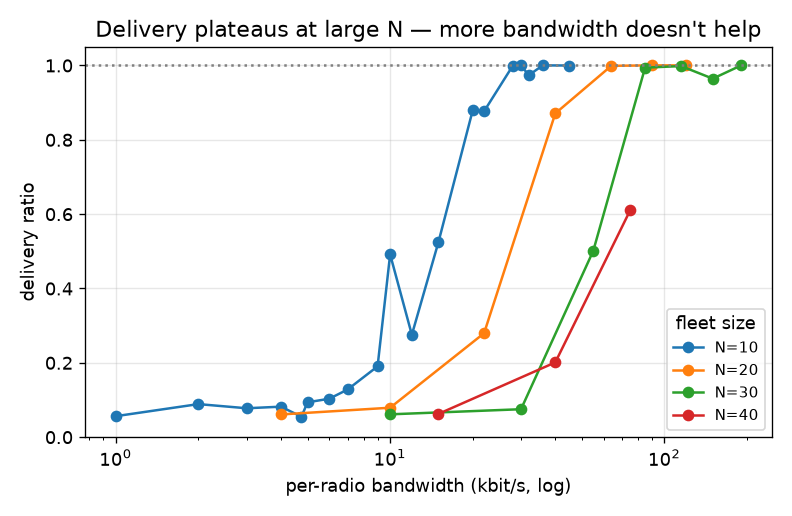
5.3 Barrier 1: delivery, latency and the (N−1) fan-out tax
Within fleets that can converge, link bandwidth is the binding constraint, and the fixtures below establish the picture (illustrated at N=10).
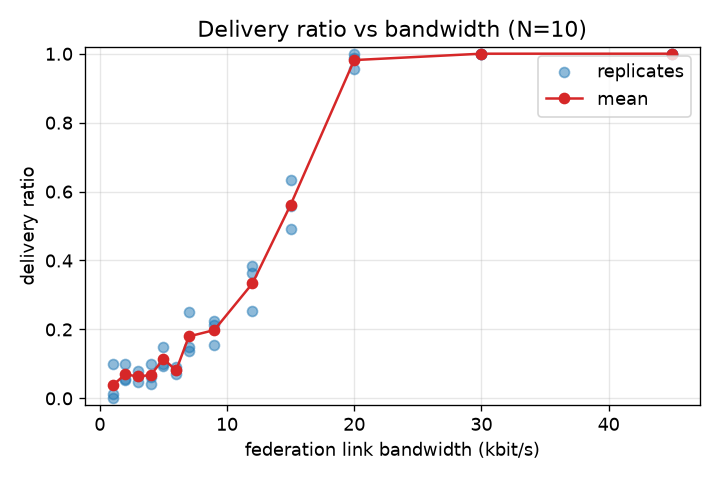
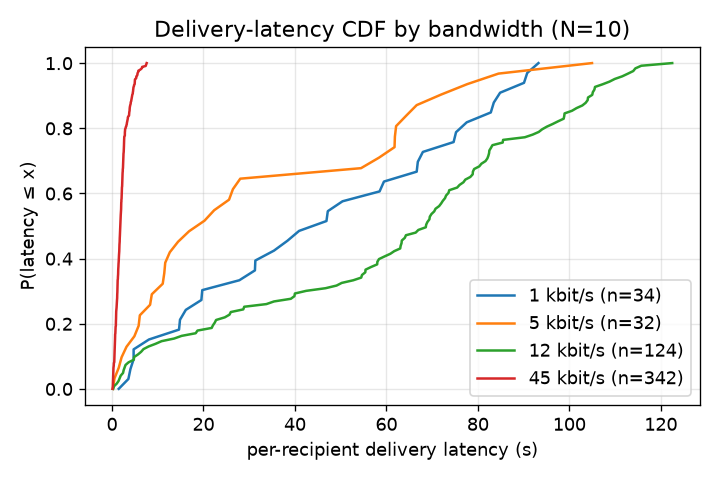
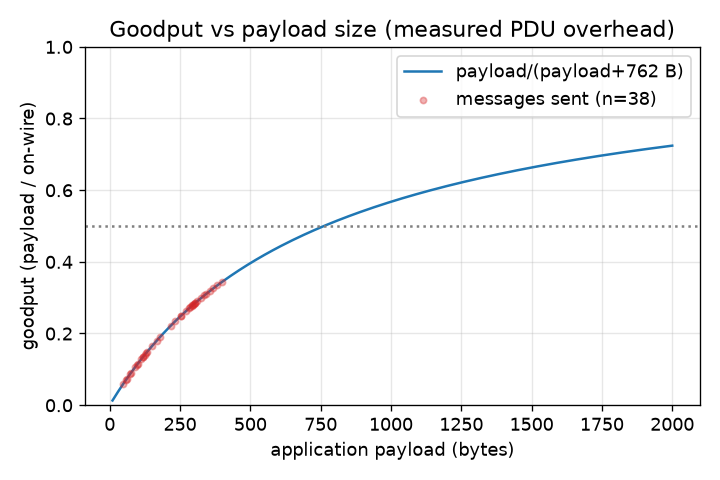
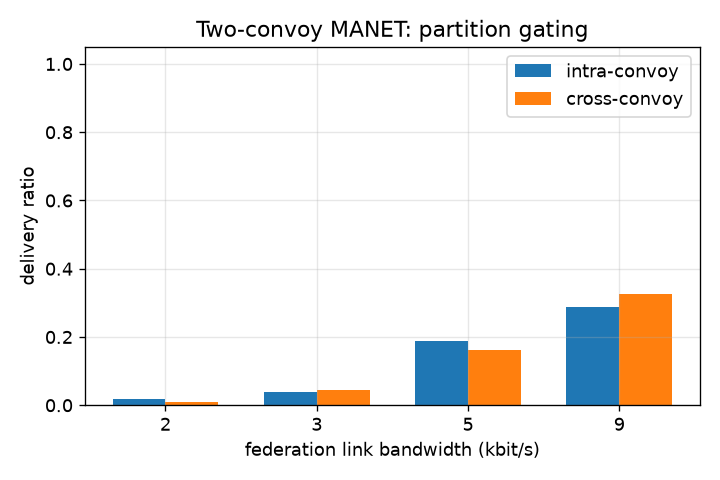
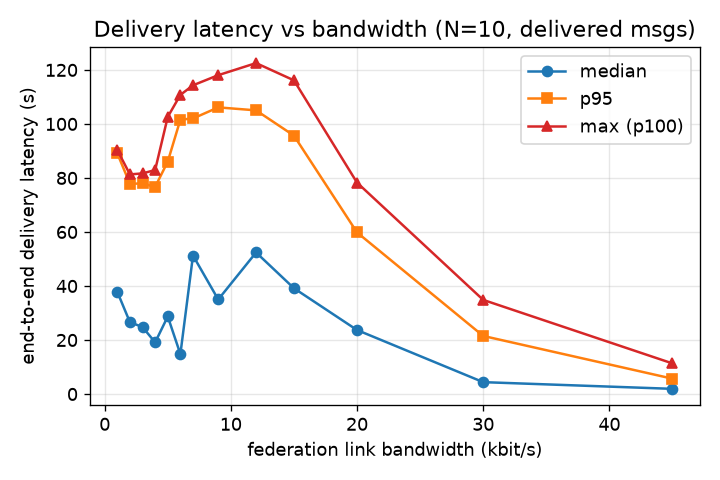
Fig. 3 and Fig. 4 establish the within-fleet picture at N=10. Delivery is a clean monotone function of link rate, and the run is fully usable (≈98–100% delivery, single-digit to ~20 s latency) only from ~20 kbit/s upward (≈100% at ~30 kbit/s) — well above the 1–9 kbit/s tactical envelope, within which delivery never exceeds ≈20%. Fig. 7 plots median and p95 latency directly against bandwidth as a companion view.
5.4 Federation overhead is fixed per message and N-independent
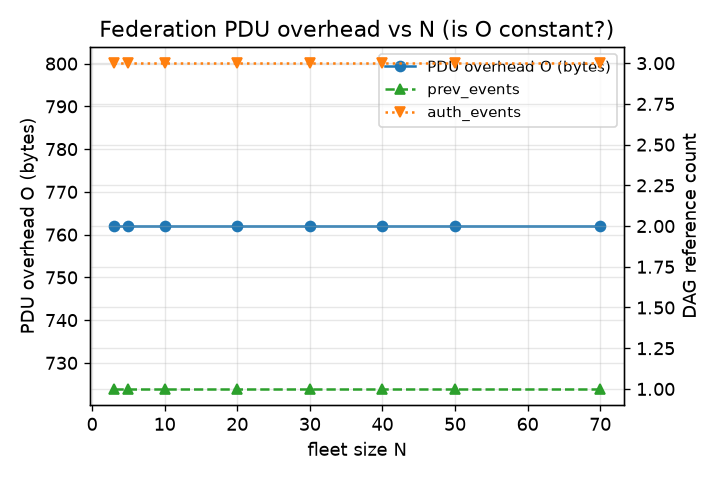
We serialised the signed federation PDU for a single-room message and measured an envelope of 762 bytes (auth_events=3, prev_events=1, one ed25519 signature, plus transaction framing) — markedly below the 1100 B we had previously estimated. The decisive property (Fig. 8) is that this 762 B is invariant in fleet size: it is the same from N=3 up to N=70. The per-message envelope does not grow with the fleet; what grows is the number of point-to-point federation transactions a sender must emit, one per peer, i.e. (N − 1) copies. This is exactly why the bandwidth cost scales with fleet size even though the per-PDU cost does not. The 762 B is the Matrix-PDU layer and excludes TLS/TCP/IP framing, so true bytes-on-wire are somewhat higher.
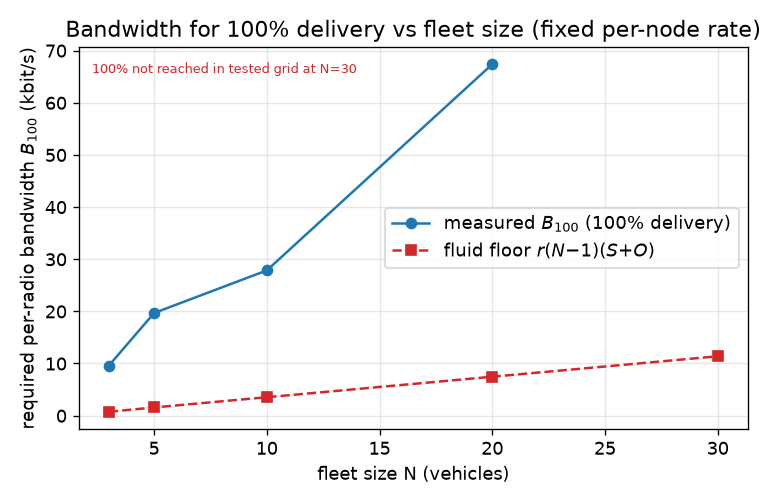
5.5 Required-bandwidth scaling law and the widening chatter tax
To turn the per-fleet curves into a scaling statement we measure B50, the link bandwidth at which delivery reaches 50%, as a function of fleet size N at a fixed per-node rate (~0.05 msg/s/node). The result (Fig. 9) grows super-linearly in N, and runs out of meaning past N=30 because of Barrier 2:
- N=3 → B50 ≈ 2.6 kbit/s (k ≈ 8.4× the fluid floor)
- N=5 → B50 ≈ 7.1 kbit/s (k ≈ 9.3×)
- N=10 → B50 ≈ 15.7 kbit/s (k ≈ 6.1×)
- N=20 → B50 ≈ 34.2 kbit/s (k ≈ 16.1×)
- N=30 → B50 ≈ 110.6 kbit/s (k ≈ 16.7×)
- N≥40 → unreachable: delivery never reaches 50% at any bandwidth tested (Barrier 2 caps it at ≤40.8%), so B50 does not exist.
The fluid byte-budget law Breq = r·(N − 1)·(S + O)
— sender rate r times the (N − 1) fan-out times payload-plus-overhead
(S≈220 B, O=762 B) — predicts the correct shape (∝ N − 1) but
massively under-predicts the magnitude, and the gap widens with N. The
inefficiency factor k = B50/Bfluid is ≈8× at N=3 and ≈9× at N=5, dips to
≈6× at N=10, then climbs to ≈16× at N=20 and ≈17× at N=30 — i.e. it grows with fleet
size rather than holding constant. (This supersedes our earlier pilot estimate of a roughly
constant ~4× multiplier; the fuller N=3–70 sweep shows the tax compounding with N.) The growing
multiplier is the protocol's RTT / request-response / chatter tax (see §6): federation is
round-trip-bound, and the round-trips multiply with peers, so achievable throughput falls
further below the raw link rate as the room grows. A naive byte count for N=70 gives only
~27 kbit/s (the fluid prediction); the measured requirement is far higher — and ultimately
moot, because Barrier 2 caps delivery at ~37% before 50% is ever in reach.
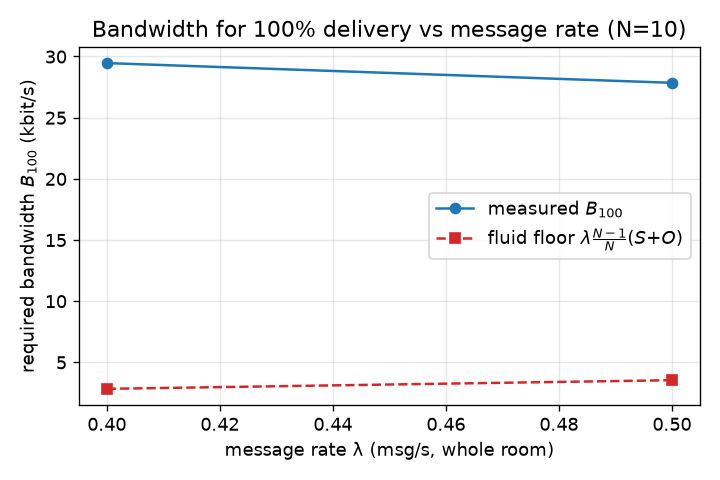
A second cut holds N fixed (N=10) and varies the per-node message rate; B50 again rises with offered load (from ~9 kbit/s at the lowest rate measured to ~19 kbit/s at 1 msg/s/node), confirming the law is driven by aggregate offered transactions rather than fleet size alone (Fig. 10).
5.6 Three non-convergence regimes
The non-convergence flags now span three qualitatively different mechanisms, which must not be conflated. (i) s0, small N (≤10) — window-limited. Absent partitions a finite backlog drains at any bandwidth B > 0, so the low delivery at throttled cells is merely the fixed-length run ending before the slow link finishes draining — not a permanent inability to deliver; given enough bandwidth (or time) these fleets reach 100%. (ii) s0, large N (≥20) — structural convergence ceiling (Barrier 2). Here delivery plateaus below 100% and the plateau is bandwidth-independent (§5.2): the logged HTTP 403 backfill failures show the room never assembles a consistent membership, so this is not a too-short window but a structural fork that more bandwidth cannot heal. (iii) s1 — structural partition starvation. Cross-convoy backlog can only drain inside heal windows and, at low bandwidth, never catches up. The honest summary is therefore not "a single bandwidth threshold" but: small rooms are window-/bandwidth-limited, while large rooms hit a hard ceiling that bandwidth does not move.
5.7 Per-run summary
| run | scenario | bw (kbit/s) | delivery | median lat (s) | goodput | non-conv. | status |
|---|---|---|---|---|---|---|---|
| loading data/summary.json… | |||||||
6. Discussion
The quantified verdict: two barriers, one conclusion. Matrix is infeasible for a 70-node tactical operational room, and the infeasibility is over-determined — it fails for two independent reasons that bind in different regimes. Barrier 1 (bandwidth / fan-out). Matrix sends one point-to-point federation transaction per peer per message, so a sender in an N-node room emits (N − 1) copies, each carrying a measured ~762 B signed-PDU envelope plus TLS framing. Where the room can converge, the per-radio bandwidth required for delivery therefore grows with fleet size — B50 measured at 2.6, 7.1, 15.7, 34.2, 110.6 kbit/s for N=3, 5, 10, 20, 30 — already an order of magnitude beyond the 1–9 kbit/s tactical link budget by N=10. Barrier 2 (the convergence ceiling), the more fundamental one. Beyond ~N=15 the room cannot converge its membership at all, so the maximum delivery achievable over any bandwidth falls to 65.8% (N=20), 51.5% (N=30), 40.8% (N=40), 38.2% (N=50), 37.3% (N=70) and stays there no matter how fat the link is. The two compose into a blunt conclusion: even where bandwidth could in principle suffice, the room cannot converge — so adding radio capacity does not rescue the design. This is the headline result.
Why Barrier 1 is worse than the byte count. The fluid byte-budget
Breq = r·(N − 1)·(S + O) captures the right shape but
under-predicts the required bandwidth by a factor that grows with N —
≈8× at N=3, ≈9× at N=5, ≈6× at N=10, ≈16× at N=20, ≈17× at N=30. (Our earlier pilot read this as
a roughly constant ~4×; the fuller N=3–70 sweep shows the multiplier compounding.) The gap is
structural: Matrix federation is request/response- and RTT-bound — make_join, backfill,
transaction acknowledgement, and key fetches are all round-trips, and they multiply with peers —
so over the high-latency links emulated here the achievable goodput is far below the raw link
rate, and increasingly so as the room grows. A naive byte count for N=70 would have said
~27 kbit/s and badly understated the problem.
Why Barrier 2 is the deeper finding. Bandwidth is a budget you can buy;
the convergence ceiling is not. The logged root cause is auth-gated federation backfill: a server
is refused an event's prev_events with HTTP 403 because it is not yet a
recognised member, yet it cannot become a member without that history. Room state forks and never
re-converges, leaving most servers seeing only ~30–40 of 70 members — the ~37% floor. No backoff
tuning, longer window, or fatter link addresses a membership-gated authorization check. This is
the qualitative result of the study, and it is a protocol-level limitation of Matrix federation
for a single large room, not a property of our emulation.
We revisit the three working hypotheses against the measured data.
H1 — opportunistic store-carry-forward governed by link rate × partition dynamics. Confirmed at small N, refuted at scale. For N≤10 the room DAG does carry cross-node messages with no Matrix-level routing, delivery is a clean monotone function of link rate (Fig. 3), and in s1 cross-convoy delivery tracks the heal windows rather than any protocol logic (Fig. 6). But the hypothesis's premise — that delivery is governed by link/partition dynamics and "not by Matrix logic" — fails for the target fleet: at N≥20 Matrix logic (membership-gated backfill) becomes the binding constraint, and the room DAG is not a usable store-carry-forward layer at 70 nodes. The study's central hypothesis is thus refuted at the design scale.
H2 — goodput collapse for short messages. Confirmed, and grounded in a measured 762 B envelope rather than an estimate. The useful-payload ratio is ≈0.22 at the representative ~220 B tactical payload and reaches 0.5 only at a 762 B payload (Fig. 5). Because the envelope is N-independent (Fig. 8), this collapse is the same at every fleet size; the 762 B is the Matrix-PDU layer and excludes TLS, so real goodput is somewhat worse.
H3 — non-convergence below a bandwidth threshold. Superseded. The hypothesis anticipated a low (~1–2 kbit/s) bandwidth threshold below which backlog drains slower than partitions create it. We instead find that the most important non-convergence is bandwidth-independent — precisely the opposite of a threshold. There are three regimes (§5.6): s0 small-N is window-/bandwidth-limited (a faster link does fix it); s0 large-N hits the structural convergence ceiling that no bandwidth moves (Barrier 2); and s1 exhibits partition starvation gated by heal windows. So the honest statement is not "a single bandwidth threshold" but "beyond N≈15 the room fails to converge for reasons bandwidth cannot address."
7. Limitations & threats to validity
- Pilot scale & replication. Two replicates per s0 cell and a two-point s1 sweep; convergence latency is noisy, so confidence intervals are wide. Trends are indicative, not statistically settled.
- N=70 is now measured, not extrapolated — but the ceiling may be config-sensitive.
This campaign measures the full N=3–70 range directly, including the 70-node design, so the
convergence-ceiling verdict (Barrier 2) is observed rather than projected. What we have
not isolated is whether that ceiling could be raised by Synapse configuration. The
Barrier-2 plateau could interact with Synapse's state-resolution behaviour and with our
closed-mesh key-fetch choice
trusted_key_servers: [](D6): with no trusted key server, a server that cannot reach an event's origin may also be unable to verify its signing key, which would compound the auth-gated-backfill 403. We attribute the ceiling to the logged backfill 403, but a configuration that pre-distributes state/keys, or uses a shared key server, might shift it. This is an open threat to the precise numbers, not to the qualitative finding. - The Barrier-1 bandwidth law is moot at large N. B50 (and any "B100") is only meaningful where the room can converge; for N≥40 delivery is capped below 50% by Barrier 2, so B50 does not exist and the bandwidth figures for the largest fleets describe a target that is never reachable. The required-bandwidth scaling law should be read as a within-convergence result (N≲30).
- Short, fixed runs. A fixed window is the right choice for comparability, but it means s0 small-N "non-convergence" is relative to that window, not proven asymptotic (§5.6). The structural claims — Barrier 2 (bandwidth-independence + logged 403) and the s1 partition regime — do not rely on the window length.
- Overhead measured at the PDU layer, not on the wire. The 762 B envelope is serialised from the signed federation PDU (auth/prev events, hashes, signatures, transaction framing) and is N-independent, but it excludes lower-layer TLS/TCP/IP framing and backfill/key-fetch round-trips. True bytes-on-wire are higher, so the goodput figures are an upper bound on real goodput; a packet capture would tighten them downward.
- Synthetic links on one box. Bandwidth, delay, and partitions are emulated
via Chaos Mesh
tc/netem on a single host. This is deliberate (control beats realism here), but it omits real radio effects — fading, MAC contention, asymmetric/jittery rates, and bit-level corruption interactions — and shares one kernel network stack. - Single 16-core host, shared resources. Despite the CPU-saturation guard, all 70 Synapses, Postgres, and the orchestrator contend for one 16-core machine; residual contention could perturb tail latency, and a synchronized backfill/heal burst at large N stresses the box more than at the validated N=10 scale.
8. Future work
- Attack the convergence ceiling (Barrier 2) directly. Pin down whether the auth-gated-backfill 403 can be worked around — e.g. pre-seeding room state/keys at join, sharding the fleet into many small rooms instead of one 70-server room, a shared key server, or a homeserver/protocol variant with a different backfill-authorization model — and measure how far each lifts the ~37% ceiling. This is the highest-value follow-up, since Barrier 2 dominates the verdict.
- Deepen replication on the medium/thorough campaigns (more bandwidths, scenarios, and 3–5 replicates) to turn indicative trends into statistically supported ones, and confirm the convergence ceiling is stable across Synapse state-resolution settings.
- Complement the measured 762 B PDU envelope with a real packet capture of the federation link to add the TLS/TCP/IP framing and measure backfill/key-fetch/reconvergence bytes per heal directly — quantifying the (growing 8–17×) RTT/chatter tax byte-for-byte.
- Enrich the link model toward real radio: add delay/jitter/loss/corruption alongside bandwidth, asymmetric rates, and contact patterns derived from vehicle mobility traces.
- Explore additional topology scenarios (more than two convoys, chained partitions, intermittent relays) and quantify how DAG reach depends on shared-room structure.
- Compare against a homeserver with a thinner federation footprint and against an explicit DTN/epidemic overlay to bound how much an active SCF layer would add over Matrix's implicit one.
References
- The Matrix.org Foundation. Matrix Specification — Server-Server (Federation) API. spec.matrix.org. [TODO: verify exact spec version cited]
- Element / The Matrix.org Foundation. Synapse: a Matrix homeserver. element-hq/synapse, GitHub. [TODO: verify version]
- K. Fall. "A Delay-Tolerant Network Architecture for Challenged Internets." Proc. ACM SIGCOMM 2003, pp. 27–34. (SIGCOMM Test-of-Time Award.)
- V. Cerf, S. Burleigh, A. Hooke, L. Torgerson, R. Durst, K. Scott, K. Fall, H. Weiss. Delay-Tolerant Networking Architecture. IETF RFC 4838 (Informational), April 2007.
- A. Vahdat and D. Becker. Epidemic Routing for Partially-Connected Ad Hoc Networks. Technical Report CS-2000-06, Duke University, 2000.
- E. M. Royer and C.-K. Toh. "A Review of Current Routing Protocols for Ad Hoc Mobile Wireless Networks." IEEE Personal Communications, vol. 6, no. 2, pp. 46–55, 1999.
- The Kubernetes Authors. Kubernetes (k3s lightweight distribution). kubernetes.io / k3s.io. [TODO: verify citation form]
- The Chaos Mesh Authors (CNCF). Chaos Mesh: A Chaos Engineering Platform for Kubernetes. chaos-mesh.org, GitHub chaos-mesh/chaos-mesh. [TODO: verify citation form]